
Data scraping has become an essential skill in today’s digital landscape. The ability to collect and analyze data quickly can determine a company’s competitive edge. But, have you ever thought of web scraping as more than just writing code? With the emergence of new AI technologies, the paradigm of web scraping is shifting. One of the most notable changes is web scraping using OpenAI’s GPT-4o. This article will explore how GPT-4o can be used to extract data and create cost-efficient scraping tools.
Advantages of Data Scraping with GPT-4o
One of the biggest advantages GPT-4o offers is its ability to extract ‘structured data’. Traditional scraping tools require analyzing HTML code and creating complex XPath queries, but GPT-4o is more efficient in this process. It can extract data directly from HTML and return it in a structured format.
A simple scraping experiment using GPT-4o shows how data can be modeled with the following code:
from typing import List, Dict
from pydantic import BaseModel
class ParsedColumn(BaseModel):
name: str
values: List[str]
class ParsedTable(BaseModel):
name: str
columns: List[ParsedColumn]In this code, data is stored in a structured format called ‘ParsedTable’, making it easy to scrape complex HTML tables. This approach can be particularly useful when extracting product information from e-commerce or news sites.
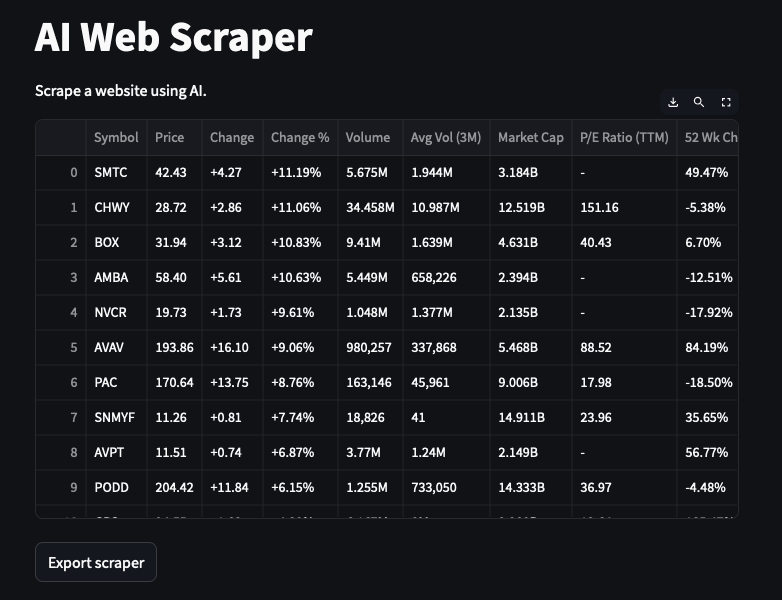
Scraping Complex Tables: The Capabilities of GPT-4o
The true test of web scraping lies not in simple tables, but in how accurately data can be extracted from complex HTML structures. In an experiment extracting 10-day weather forecast data from sites like Weather.com, GPT-4o showed the ability to add Day/Night columns, providing more specific data.
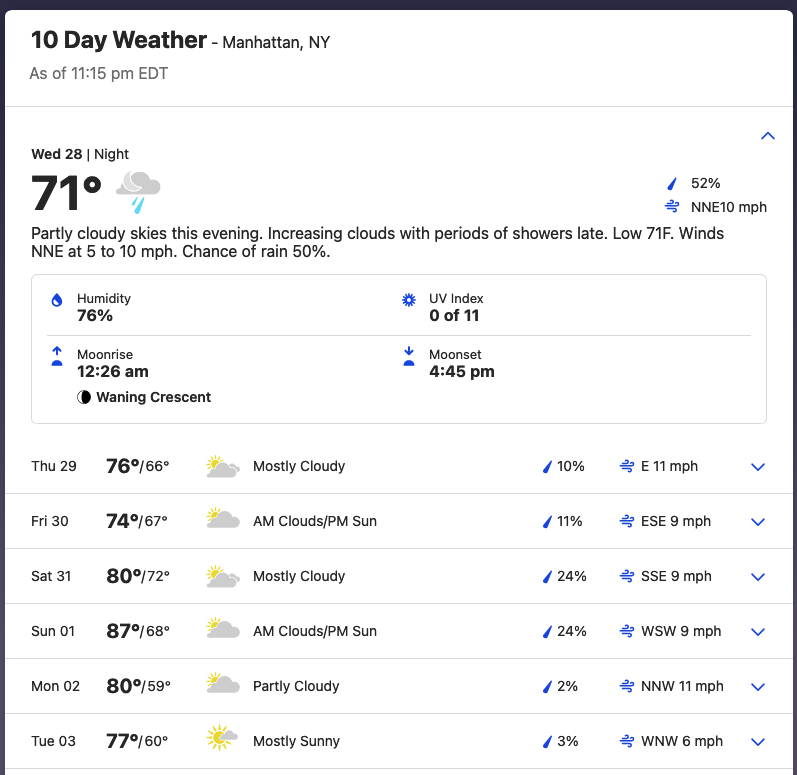
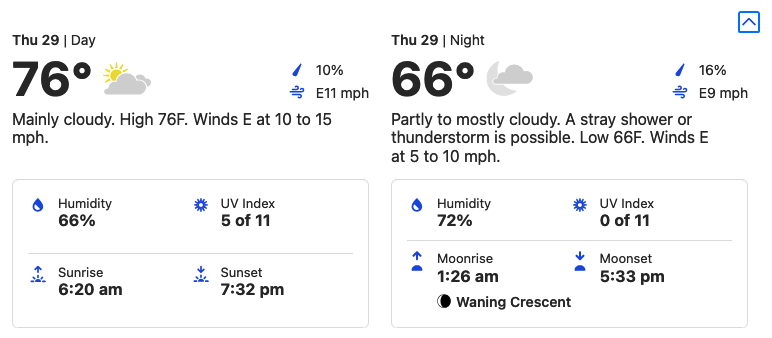
What was particularly interesting was that even though the Condition column was not visible, GPT-4o accurately read the source code and returned the data. This shows that the AI is not merely predicting data but analyzing the actual HTML source.
Challenges with Merged Rows
However, not everything is perfect. For instance, when testing the Human Development Index table from Wikipedia, the model struggled to handle merged rows. This issue can arise in specific data structures, and additional work is needed to improve the AI model’s accuracy in these cases.

Limitations and Improvements for GPT-4o
Cost issues are one of the main drawbacks of using GPT-4o for web scraping. Extracting large volumes of data can lead to significant API call costs. A workaround approach was attempted by requesting the model to return XPath queries, but this often led to less accurate results than expected.
A Combined Approach
In the end, a better approach was to first extract the data and then request XPath based on that extraction. This method provided more accurate results while reducing costs. However, there are still issues when extracting image data instead of text, which can lead to errors.
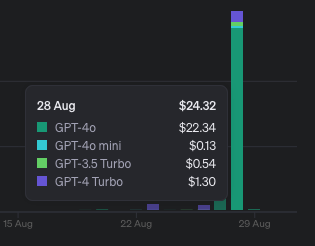
Conclusion: The Future of AI and Web Scraping
In conclusion, web scraping with GPT-4o is a powerful tool. The ability to extract accurate data from HTML strings showcases the new possibilities of AI technology. However, there are still cost and technical limitations to address. More experiments and research are required to overcome these challenges.
In combination with traditional scraping tools like BeautifulSoup and Scrapy, GPT-4o can create even more powerful web scraping tools. The future of AI-powered web scraping looks promising.
Source: blancas.io, “Using GPT-4o for web scraping”