
Meta is one of the leading companies in today’s tech industry, continuously striving to train large language models (LLMs). This training process involves more than just handling vast amounts of data; it requires immense computational power and poses significant technical challenges. In this article, we will explore how Meta overcomes these challenges and successfully trains large language models. We will also discuss the hardware and software issues they face, the solutions they implement, and future prospects for this work.
Challenges in Large-Scale Model Training
Hardware Reliability
One of the biggest challenges in large language model training is hardware reliability. Meta performs rigorous testing and quality control to minimize interruptions caused by hardware failures during training. This process focuses on quickly detecting and recovering from hardware failures, especially those occurring during training. For instance, rapid recovery after a failure reduces rescheduling overhead and allows training to resume quickly.
Optimal Connectivity Between GPUs
Another critical factor in large language model training is the optimal connectivity between GPUs. To address this, Meta has built high-speed network infrastructure and employs efficient data transfer protocols. The speed of data transfer between GPUs has a significant impact on the overall training time for large models.

Improvements in the Infrastructure Stack
Training Software
Meta supports researchers using open-source software like PyTorch to rapidly move from research to production. To achieve this, Meta develops new algorithms and techniques and integrates them into its training software. This approach enhances the efficiency of Meta’s large-scale training operations.
Scheduling
Meta uses complex algorithms to dynamically allocate and schedule resources based on the needs of the tasks in large-scale training. This allows for more efficient use of resources and contributes to faster, more effective training.

Data Center Placement and Reliability
Data Center Placement
Meta optimally places GPUs and systems in data centers to maximize resources such as power, cooling, and networking. This enables Meta to achieve the highest possible computing density and optimize training efficiency. This approach plays a key role in helping Meta maintain a competitive edge in large language model training.
Reliability
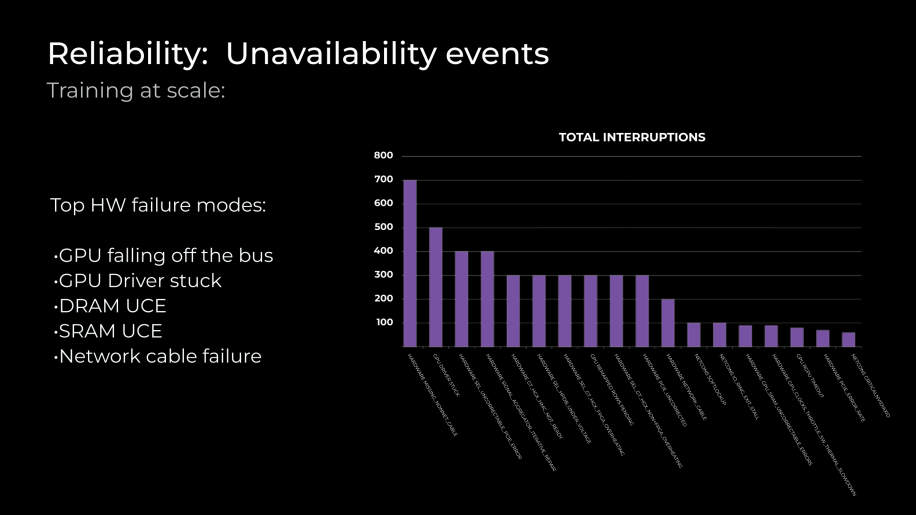
To minimize downtime in the event of hardware failures, Meta has established detection and recovery plans. This reduces interruptions caused by hardware failures and allows for quick recovery. Common failure modes include GPU detection issues, DRAM & SRAM UCEs, and hardware network cable problems.
Future Prospects
In the future, Meta plans to handle more data and deal with longer distances and latencies by using hundreds of thousands of GPUs. To achieve this, Meta will adopt new hardware technologies and GPU architectures and continue to evolve its infrastructure. Through these efforts, Meta aims to push the boundaries of AI and meet the challenges of a rapidly evolving environment.
Conclusion
Meta’s training of large language models is filled with immense technical challenges and opportunities. Throughout this process, Meta optimizes hardware reliability, GPU connectivity, training software, and data center placement and reliability. By doing so, Meta maintains a competitive edge in the evolving field of AI and continues to lead in future technological advancements.
Reference: engineering.fb.com, “How Meta trains large language models at scale”